Splunk Components
Usando um único componente de software que é fácil de entender em suas configurações, o Splunk Enterprise pode coexistir com a infraestrutura existente ou pode ser implantado como uma plataforma universal para acessar dados de TI. A implementação mais simples é aquela obtida por padrão ao instalar o Splunk Enterprise: Indexando, pesquisando e exibindo dados no mesmo servidor.
Em seguida, os principais componentes que constituem uma implementação do Splunk; de forma mais simples até as mais sofisticadas.
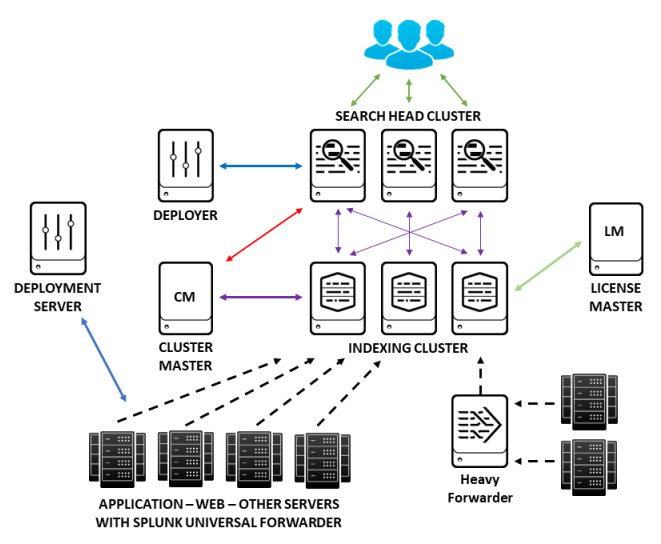
Indexer
- Processa dados de máquina, armazenando os resultados em índices como eventos, permitindo pesquisa e análise rápidas.
- Conforme o indexador indexa dados, ele cria vários arquivos organizados em conjuntos de diretórios por idade.
- Contêm dados brutos (compactados) e índices (aponta para os dados brutos). (Dados raw)
Search Head
- Permite que os usuários usem a pesquisa para buscar os dados indexados
- Distribui solicitações de pesquisa do usuário para os indexers
- Consolida os resultados e extrai pares de valores de campo dos eventos para o usuário
- Knowledge Objects podem ser criados para extrair campos adicionais e transformar os dados sem alterar os dados de índice subjacentes
- Ainda fornecem ferramentas para aprimorar a experiência de pesquisa, como relatórios, painéis e visualizações.
Forwarders
- Instâncias do Splunk Enterprise que consomem e enviam dados para o(s) Indexer(s)
- Requer recursos mínimos e tem pouco impacto no desempenho
- Normalmente residem nas máquinas os dados se originam
- Geralmente primeira forma de coleta e fornecimento de dados para indexação
Heavy Forwarder
- Um tipo de encaminhador, que é uma instância do Splunk Enterprise que envia dados para outra instância do Splunk Enterprise ou para um sistema de terceiros.
- Um Heavy Forwarder ocupa menos espaço do que um indexador do Splunk Enterprise, mas retém a maioria dos recursos de um indexador. Uma exceção é que ele não pode realizar pesquisas distribuídas. Você pode desabilitar alguns serviços, como o Splunk Web, para reduzir ainda mais o tamanho do seu espaço físico.
Deployment Server
- Responsável por gerenciar e centralizar toda configuração dos coletores (Forwarders)
- Também pode ser utilizado para distribuir apps para o master node e para o Deployer. Não pode ser utilizado para distribuir apps para os membros do cluster de Search Heads.
- O Deployment Server lida com as atualizações de configuração e conteúdo das instalações existentes do Splunk Enterprise.
- Você não pode usá-lo para instalações iniciais ou de atualização do Splunk Enterprise ou do Universal Forwarder.
Cluster Master
- O Master Node gerencia o Cluster. Ele coordena as atividades de replicação dos nós pares e informa ao Search Head onde encontrar os dados.
- Ajuda a gerenciar a configuração de nós de pares e orquestra atividades corretivas se um par fica offline. Ao contrário dos nós pares, o master node não indexa dados externos.
- Um cluster possui exatamente um master node.
License Master
- Um License Master - LM controla um ou mais slaves license - SL.
- Há dois modelos de LM, Standalone license master e Central license master
- No LM, você pode definir pilhas, pools, adicionar capacidades de licenciamento e gerenciar as instâncias SL.
- Ao receber event data, o volume de dados medido é baseado nos dados brutos (raw) que são colocados no pipeline de indexação.
- Não se baseia na quantidade de dados compactados gravados no disco. Como os dados são medidos no pipeline de indexação, os dados filtrados e descartados antes da indexação não contam na cota de volume de licença.
04 Passos para implantação simples:
- Download do arquivo de instalação através do site oficial;
- Instalação em seu ambiente (Windows, Linux, Mac, etc)
- Encaminhar os dados que deseja (Logs, scrits, arquivo .csv, etc);
- Após esses passos estará disponível para buscas, criação de alertas, visualizações, Dashboards, etc;
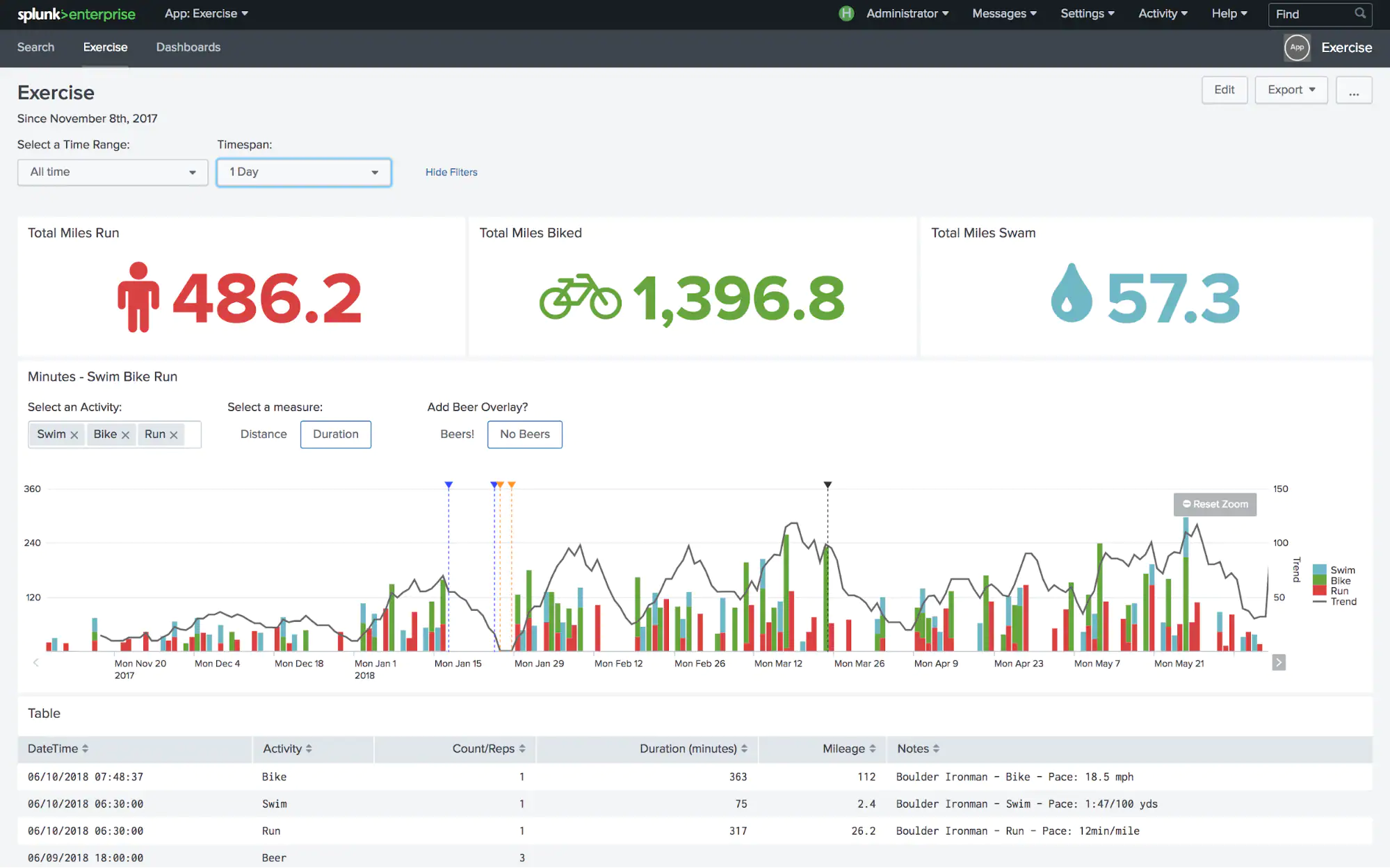
Dashboard de Exemplo: