
Arquitetura de Splunk:
- Envie os dados de milhares de dispositivos usando qualquer combinação de Splunk Forwarders
- Encaminhamento com balanceamento de carga automático para os Indexers
- Descarregar a carga de pesquisa para as Search Heads
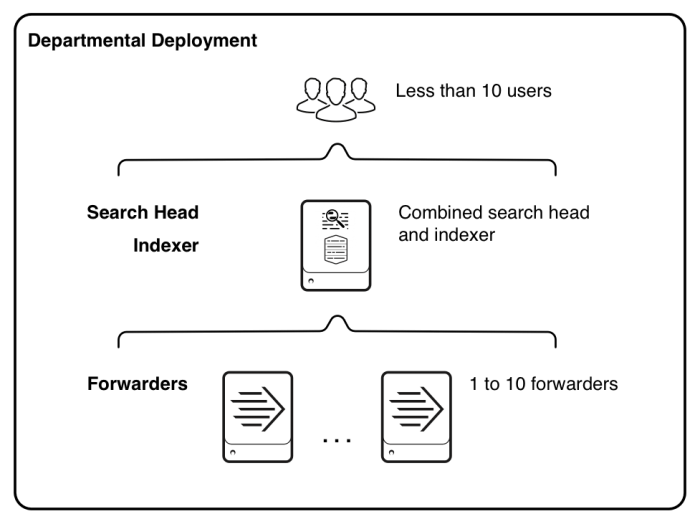
Implantação de Servidor Único
- Você não tem nenhum requisito para fornecer alta disponibilidade ou recuperação automática de desastres neste modelo
- Sua ingestão diária de dados está abaixo de 300GB/dia
- Você tem um pequeno número de usuários com dados não críticos casos de uso de pesquisa
- 1) Sem alta disponibilidade para pesquisa/indexação; 2) Escalabilidade limitada pela capacidade do hardware (Caminho de migração direto para uma implantação distribuída)
Implantação distribuída não clusterizada
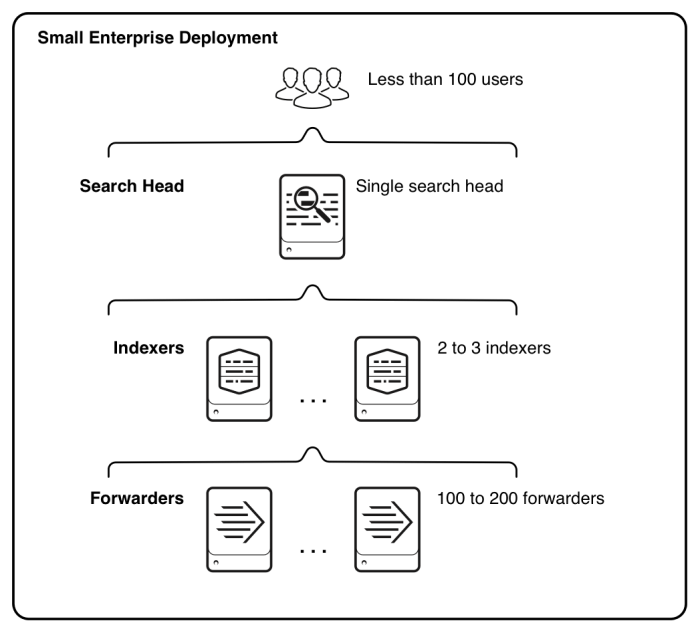
- Seu volume de dados diário a ser enviado ao Splunk excede a capacidade de implantação de um único servidor.
- Você deseja/precisa fornecer ingestão de dados altamente disponível. A implantação de vários indexadores independentes permitirá que você dimensione sua capacidade de indexação linearmente e aumente implicitamente a disponibilidade para ingestão de dados.
- Limitações: Sem alta disponibilidade para nível de pesquisa; alta disponibilidade limitada para a camada de indexação, a falha do nó pode causar resultados de pesquisa incompletos para pesquisas históricas, mas não afetará a ingestão de dados.
Implantação Clustering - Site Único
- Esta topologia apresenta arrajo de indexers em conjunto com uma política de replicação de dados configurada apropriadamente.
- Isso fornece alta disponibilidade de dados em caso de falha de um nó de mesmo nível do indexador. Isso se aplica apenas à camada de indexação e não protege contra falhas nas Search Heads. Search Heads independentes/adicionais podem ser usados por motivos de disponibilidade/capacidade ou para executar soluções de aplicativos premium do Splunk, como Splunk Security, embora a abordagem recomendada para dimensionar a capacidade de pesquisa seja empregar Search Head Clustering.
- Limitações: Sem alta disponibilidade para nível de pesquisa; Número total de buckets exclusivos no cluster do indexador limitado a 20MM (V8.X), buckets totais de 40 MM; Sem capacidade de DR automática em caso de interrupção do Data Center.
Arquitetura Multi-Cloud
- A pesquisa distribuída unifica a visão em todos os locais
- O acesso baseado em funçaõ controla até que ponto a pesquisa de um determinado usuário se estenderá
Clustering
- Replicação de dados - Mantenha a capacidade de pesquisa mesmo se os servidores caírem
- Capacidade para vários sites - Mantêm a capacidade de pesquisa mesmo se um site cair
- Afinidade de pesquisa - Otimiza pesquisas buscando do local mais próximos/mais rápido
Pipeline de Indexação
- Dados em tempo real e histórico no local, na nuvem ou em ambos
- Mais de 140 comandos, incluindo detecção de anomalias e aprendizado de máquina
- Uma vez que os dados foram adicionados a um index, você não pode editar ou alterar os dados. VOcê pode excluir todos os dados de um index ou pode excluí-lo e, opcionalmente, arquivar, intervalos de índice individuais com base na política, mas não pode excluir seletivamente eventos individuais do armazenamento
Ex: Data (TCP, UDP, Script) –> Parsing Queue –> Parsing Pipeline –> Index Queue –> Real-Time Buffer (Search Proccess) / Indexing Pipeline (Raw Data Index Files)